Почтовое отделение БАЛЕЗИНО 3 (ОПС) обслуживает индекс 427553 в регионе Удмуртия, Балезинский район. Ознакомьтесь с информацией о режиме работы отделения, узнайте как добраться и оставьте отзывы о качестве предоставляемых услуг.
Реквизиты почтового отделения БАЛЕЗИНО 3
| Адрес: | Кирова ул, 41, Балезино, Балезинский район, Удмуртская республика |
| Телефон: | 8 (800) 100-00-00 - Прочее |
| Режим работы: | Пн: выходной Вт: 09:00-17:00 перерыв: 12:00-13:00 Ср: 09:00-17:00 перерыв: 12:00-13:00 Чт: 09:00-17:00 перерыв: 12:00-13:00 Пт: 09:00-17:00 перерыв: 12:00-13:00 Сб: 09:00-17:00 перерыв: 12:00-13:00 Вс: выходной |
Образец заполнения почтового индекса




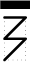
Список обслуживаемых адресов
| Улица | Номера домов |
|---|---|
| Пибаньшур деревня, Вокзальная ул. | 1, 2, 3 |
| Пибаньшур деревня, Железнодорожная ул. | 1, 2, 3, 4, 5, 6, 7, 8 |
| Пибаньшур деревня, Крайняя ул. | 1, 2, 4 |
| Пибаньшур деревня, Полевая ул. | 1, 2, 3, 4, 5, 6 |
| Пибаньшур деревня, Центральная ул. | 1, 2, 4, 6 |
| Русский Пибаньшур деревня, Все номера домов | |
| Балезино-3 поселок, Кирова ул. | 1, 2, 4, 5, 6, 7, 8, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 36, 39, 41 |
| Балезино-3 поселок, Космонавтов ул. | 32, 32А, 33, 34, 35 |
| Балезино-3 поселок, Свердлова ул. | 11, 12, 13, 14, 15, 16, 17, 18, 20 |
| Дома 1214 км починок, Все номера домов | |
| Дома 1214 км починок, Все номера домов | |
| Дома 1214 км починок, Все номера домов | |
| Дома 1214 км починок, Все номера домов |
Отзывы об отделении БАЛЕЗИНО 3, 427553
К сожалению, пока у нас нет ни одного отзыва об этом почтовом отделении. Будьте первым!
Оставьте свой отзыв